 |
| credit: SkipsterUK (CC BY-NC-ND 2.0) |
Preamble
In the previous post in this series, I explained how to use causal diagrams to set up multivariate regressions so that statistical confounding is eliminated.
In this post, I'll give a short and simple example of a case where statistical confounding can't be prevented, because an important variable is unavailable. This sort of thing is unfixable, and it is bound to happen sometimes in observational statistical analyses, because there are influencing variables that we just don't anticipate, and therefore don't collect.
Here's the entire 'statistical confounding' series:
Part 1: Statistical confounding: why it matters
- on the many ways that confounding affects statistical analyses.
Part 2: Simpson's Paradox: extreme statistical confounding
- understanding how statistical confounding can cause you to draw exactly the wrong conclusion.
Part 3: Linear regression is trickier than you think
- a discussion of multivariate linear regression models
Part 4: A gentle introduction to causal diagrams
- a causal analysis of fake data relating COVID-19 incidence to wearing protective glasses.
Part 5: How to eliminate confounding in multivariate regression
- how to do a causal analysis to eliminate confounding in your regression analyses
Part 6: A simple example of omitted variable bias (this post)
- an example of statistical confounding that can't be fixed, using only 4 variables.
Omitted variable bias
Suppose we have a dataset whose rows consist of the following three variables:
- $P$: the score of a parent on a general well-being measure, a continuous variable.
- $C$: the score of a child on a general well-being measure, a continuous variable.
- $T$: whether or not the parent received counseling (therapy), a binary variable.
Presumably, if the parent receives therapy, that would increase the parent's well-being score, and through the parent would also increase the child's well-being score. This would create a positive association between therapy and the child's well-being score. The image below shows how the associated causal diagram would look.
But we can also ask whether the therapy improves the child's well-being score in a direct way, i.e., not as an indirect effect of the parent's improved well-being score.
We ask this question by doing a regression of the child's well-being score (as the independent variable) on the therapy variable. In order to determine whether there is a direct effect of a parent's therapy on a child's well-being, we need to condition on the parent's well-being score by including it in the regression model; this blocks the indirect effect of the parent's improved well-being on the child's well-being.
A simple model regressing $C$ on $T$, and including $P$ as a covariate, might look like this:
$$
\begin{aligned}
C &\sim N(\mu, \sigma^2) \\
\mu &= \alpha_{[T]}+\beta P\\
\alpha_{[T]} &\sim N(\alpha_{0}, \sigma_T) \\
\beta &\sim N(\beta_0, \sigma_P)
\end{aligned}
$$
The key to understanding this model is the line:$$\mu=\alpha_{[T]} + \beta P.$$ This line says that we are modeling the mean value of the well-being score $C$ as a sum of two terms. The first is an intercept $\alpha_{[T]}$, for $T=0$ or $1$, that depends on whether the parent is receiving therapy; this measures the direct effect of the therapy on $C$, and it's the term we're really interested in for this regression. The second term involves a slope parameter $\beta$ that measures the effect on $C$ of an increase in the parent's well-being variable $P$; this is how we incorporate conditioning on $P$ into the model. The values $\alpha_0, \sigma_T, \beta_0$, and $\sigma_P$ are just constants defining the prior distributions of $\alpha_{[T=0]}, \alpha_{[T=1]}$, and $\beta$.
Of course, it's hard to imagine that there would be a direct effect of the parent receiving therapy on the child's well-being, and that's what you'd expect such a regression to show: an insignificant difference between the posterior distributions of $\alpha_{[T=0]}$ and $\alpha_{[T=1]}$.
However, the most likely result of the regression would be that $\alpha_{[T=0]} > \alpha_{[T=1]}$. That is, the direct influence of a parent's receiving therapy, after conditioning on the parent's well-being, would be to paradoxically reduce the child's well-being score!
The reason for this odd effect is that there are likely to be lurking variables -- variables we didn't measure or include in the regression -- that impact both the parent's and the child's well-being scores.For example, consider the influence of the family's finances on both the parent and child; having enough money for a comfortable life is highly likely to improve both the parent's and child's well-being. Call this variable $F$, for the family's annual income. The image below shows how this omitted variable affects the causal diagram: the variables inside the dotted rectangle are the only ones we have actually observed.
We cannot condition on the variable $F$ (i.e., we can't include it in the regression), because we don't know its value. But it will still cause confounding of the results.
That's because the silent presence of $F$ has turned $P$ into a collider variable in the causal diagram. Collider variables were discussed in the previous post on this topic (How to eliminate confounding in multivariate regression). A collider is a variable in a causal diagram, occurring in a path between an independent variable and a dependent variable of interest, that has two arrows pointing into it from its two adjacent variables.
In this case, the path running from $T$ through $P$ to $F$ and then to $C$ contains $P$ as a collider variable. Because $P$ is a collider in this path, including it in the regression creates a negative association between $F$ and $T$, for reasons explained below. Because the general effect of increasing finances on the child's well-being score is positive, the negative association between $F$ and $T$ creates a negative association between $C$ and $T$, and that causes the weird regression result.
Why does conditioning on the collider variable $P$ create a statistical association between $F$ and $T$? Because conditioning on $P$ means that you have told the statistical model what the value of $P$ is. Once you know $P$, that lets you make inferences about the value of $F$ if you already know $T$, and vice versa.
To see how that can happen, let's suppose that you've learned that the parent's well-being score $P$ is high. If you then learn that the family is poor (low $F$), this suggests that the parent's well-being is coming from the other source in the causal diagram, therapy (i.e., it is more likely that $T=1$). Conversely, if $P$ is low, and you then learn that the family is well-off, that suggests that the parent's lower well-being score is related to the other causal variable in the causal diagram (i.e., it is more likely that $T=0$). So for any fixed and known value of $P$, $T$ is more likely to be 0 when the family finances are better, and more likely to be 1 when the family finances are worse.On the other hand, if we don't know the value of $P$, then there is no relationship between $T$ and $F$. We say that $T$ and $F$ are marginally independent, and conditionally dependent given $P$.
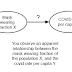
In general, we know that both therapy and good finances are likely to positively impact a parent's well-being score. Suppose $P$ takes on values from 1 (lowest well-being) to 4 (highest well-being). Then we expect that for a fixed income $F$, $P$ will be higher on average for people receiving therapy. Similarly, for a fixed value 0 or 1 of $T$, $P$ will be higher on average if $F$ is higher. This results in a graph like the one below, where level sets of $P$ for values of $F$ and $T$ are shown as lines with a negative slope. Conditioning on $P$ means restricting the values of $F$ and $T$ to one of those level set lines, producing the negative association between $F$ and $T$.
The negative association between $F$ and $T$ that is set up when we condition on $P$ may not be strong, but it doesn't take much to produce a result that shows a weird negative association between a parent's therapy and a child's well-being. But it would be wrong to conclude that the relationship is causal.
This is a situation in which the statistical confounding can't be fixed. If we don't condition on $P$, then we will be measuring the positive association between therapy and a child's well-being caused by the parent's well-being. If we do condition on $P$, then because we do not know the value of $F$, we'll be measuring the non-causal negative association between $T$ and $F$, which translates to a negative association between $T$ and $C$. Either way, we aren't measuring the true direct impact of the parent's therapy on the child's well-being.This is why randomized controlled experiments are the gold standard for making causal inferences; they break up the influence of omitted variables on the measured variables, thereby solving the omitted variable problem.






No comments:
Post a Comment